Hoy vamos a hablar sobre Horizontal Pod Autoscaling (HPA para los amigos).
## ¿Qué es HPA?
Es una funcionalidad que ajusta automáticamente el número de pods en un deployment, replicaset o statefulset de "forma automática", según el uso de métricas personalizadas.
Con lo que nos lleva a nuestra siguiente pregunta:
## ¿Qué es una métrica personalizada?
Se basan en cualquier métrica que un objeto de Kubernetes informe en un cluster, como la cantidad de solicitudes de un cliente por segundo, la escritura de E/S por segundo, el uso de CPU o memoria, entre otros.
## ¿Por qué es importante HPA?
Porque es una manera de ahorrar ~~recursos~~ dinero, billete, cash, marmaja, etc. haciendo que la cantidad de pods crezca cuando se cumpla una política de uso en las métricas y disminuya la cantidad de pods cuando esté bajo del umbral.
Imagina que tu aplicación creará pods cuando sea necesario y los eliminará cuando no sean necesarios.
## ¿Cómo funciona HPA?
1. Recolección de métricas.
2. Evaluación de políticas que se hayan definido en la aplicación.
3. Ajuste de replicas, es decir, ajuste del número de pods que se crean o se eliminan.
## Manos a la obra
Para tener disponible HPA hay que cumplir unas dependencias:
1. Instalar metric-server.
2. Configurar HPA en la aplicación o en el manifest.
### Instalación de metric-server
Si estás usando un servidor de un solo nodo master usa este link:
```bash
kubectl apply -f https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml
```
Si estás usando un clusterde k8s con HA usa este link:
```bash
kubectl apply -f https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/high-availability.yaml
```
Para minikube solo tienes que hacer:
```bash
minikube addons enable metrics-server
```
Ahora verificamos que se haya instalado:
```bash
kubectl get pods -n kube-system | grep metrics-server
```

Ahora podemos obtener las métricas de nuestro cluster:
```bash
kubectl top nodes
kubectl top pods -A #Para ver todos o puedes usar -n nombredelnamespace
```

Y podemos ver los deployments que usen hpa (en estos momentos no mostrará nada pero ya vamos a hacer uno).
```bash
kubectl get hpa -A
```
## Ejemplo de configuración de HPA en una aplicación
Vamos a configurar HPA en nuestra aplicación, en este caso usaré nginx, nota que usaré los valores de CPU de 10m y 11m y que no tengo especificado la cantidad de réplicas.
Vamos a crear 4 archivos:
1. 00-namespace.yaml
2. 01-deployment.yaml
3. 02-service.yaml
4. 03-hpa.yaml
**00-namespace.yaml**
---
apiVersion: v1
kind: Namespace
metadata:
name: hpa-test
**01-deployment.yaml**
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
namespace: hpa-test
labels:
app: nginx
spec:
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
resources:
requests:
cpu: 10m
limits:
cpu: 11m
**Nota:** usamos resource requests y limits de CPU en el ejemplo puse valores de 10m y 11m, y date cuenta que no tengo especificado la cantidad de réplicas. También puedes hacer lo mismo con la memoria.
**02-service.yaml**
---
apiVersion: v1
kind: Service
metadata:
name: nginx-service
namespace: hpa-test
spec:
selector:
app: nginx
ports:
- protocol: TCP
port: 80
targetPort: 80
type: LoadBalancer
**Nota:** en mi caso en type: uso LoadBalancer porque tengo metallb en mi cluster, si no lo tienes deberás usar NodePort y deberás crear un port-forward para acceder al nginx.
**03-hpa.yaml**
---
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: nginx-hpa
namespace: hpa-test
spec:
scaleTargetRef:
kind: Deployment
name: nginx-deployment
apiVersion: apps/v1
minReplicas: 1
maxReplicas: 10
metrics:
- resource:
name: cpu
target:
type: Utilization
averageUtilization: 20
type: Resource
Presta atención a minReplicas y maxReplicas, por default iniciará con 1 solo pod, pero cuando tenga un uso mayor 20% de CPU, se crearán 10 nuevos pods.
**Nota:** esos valores son de ejemplo, a ti te tocará hacer pruebas para sacar los mejores valores para tu aplicación.
Si quisieras usar la memoria para el HPA puedes usar:
---
...
metrics:
- type: Resource
resource:
name: memory
target:
type: AverageValue
averageValue: 10Mi # este valor es un ejemplo.
Guarda todos los archivos en una carpeta y ejecuta:
```bash
kubectl apply -f .
```
Después de unos minutos (minuto y medio aprox.) podrás ver que ya se están mostrando los valores de hpa:
```bash
kubectl get hpa -n hpa-test
```

## Probando HPA
Te recomiendo que abras 3 terminales, en dos de ellas ejecutarás estos comandos respectivamente:
Terminal 1:
```bash
watch -n 1 "kubectl get hpa -n hpa-test"
```
Terminal 2:
```bash
watch -n 1 "kubectl get pods -n hpa-test"
```
Y en la Terminal 3: vamos a generar tráfico para estresar y subir el cpu, puedes abrir un navegador y dejar F5 presionado o puedes ejecutar el siguiente script:
```bash
#!/bin/sh
while true; do
curl http://URL:PORT
done
```
Guardamos el archivo como traffic.sh, le damos permisos de ejecución y lo ejecutamos:
```bash
chmod +x traffic.sh
./traffic.sh
```
Al cabo de unos minutos verás qué:
Terminal 1:
Como sube el uso del CPU.
Terminal 2:
Como se empiezan a crear los pods hasta llegar al valor de maxReplicas: 10

Ahora puedes detener el script y al cabo de unos 2-3 minutos se empezarán a destruir los pods hasta quedar en minReplicas: 1
¡Felicidades funciona!
### Qué tal si te digo que podemos configurar con más detalle HPA scaleUp, scaleDown y policies
Vamos a configurar más a detalle el comportamiento de HPA (ahorrando más dinero $$$).
Editamos nuestro archivo 03-hpa.yaml:
---
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: nginx-hpa
namespace: hpa-test
spec:
scaleTargetRef:
kind: Deployment
name: nginx-deployment
apiVersion: apps/v1
minReplicas: 1
maxReplicas: 10
metrics:
- resource:
name: cpu
target:
type: Utilization
averageUtilization: 20
type: Resource
behavior:
scaleDown:
stabilizationWindowSeconds: 30
policies:
- type: Pods
value: 1
periodSeconds: 30
scaleUp:
stabilizationWindowSeconds: 30
policies:
- type: Pods
value: 1
periodSeconds: 30
Mira que hemos agregado una nueva sección llamada behavior, que contiene dos secciones: scaleUp y scaleDown.
Con esta sección definimos el tiempo de estabilización de la aplicación y las políticas de escalado hacia arriba y hacia abajo, es decir, le configuramos cuando el cluster debe crear más pods y cuando debe eliminar los pods dejando la aplicación en el estado deseado (minReplicas). Y en este ejemplo estará escalando hacia arriba o hacia los pods de 1 en 1 cada 30 segundos. A diferencia del ejemplo inicial, que crea los 10 pods de una vez cuando estresamos la aplicación.
### Tip cálculo de pods
Para sacar el cálculo de los valores deberás usar la siguiente fórmula:
desiredReplicas = ceil[currentReplicas * ( currentMetricValue / desiredMetricValue )]
Donde:
- currentReplicas: Es el número actual de réplicas del pod que está siendo escalado.
- currentMetricValue: Es el valor actual de la métrica que se está utilizando para escalar (por ejemplo, el uso actual de la CPU).
- desiredMetricValue: Es el valor deseado de la métrica que se está utilizando para escalar (por ejemplo, el uso deseado de la CPU).
- ceil(): Es una función que redondea hacia arriba al número entero más cercano.
Recuerda que para ver el máximo de pods, CPU y memoria de cada nodo puedes hacer un:
```bash
kubectl describe nodes
```
Esto te mostrará todos los nodos y te tocará buscar la sección **Allocated resources**:
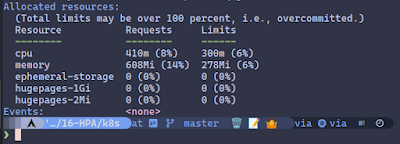
o puedes hacer:
```bash
kubectl describe nodes NOMBREDELNODO-1 NOMBREDELNODO-2
```
Hasta aquí el uso de HPA, puedes configurar lo más detallado posible para ahorrar ~~recursos~~ dinero y maximizar la elasticidad de tu aplicación.
Cualquier duda en la caja de comentarios.







No hay comentarios.:
Publicar un comentario